Introduction to RAG
this Chapter consist of general overview and definition of Rag methodologies.
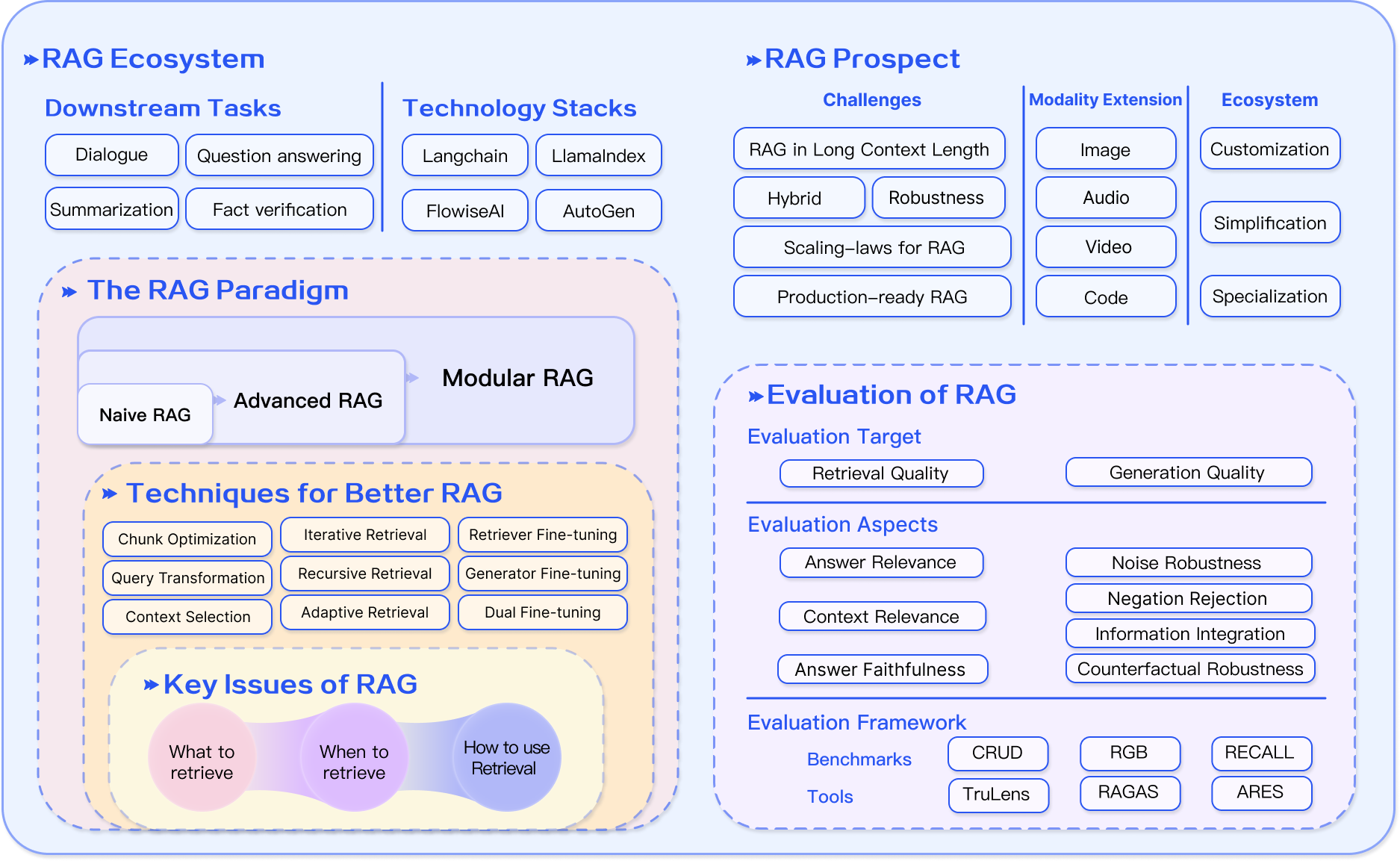
References
What is RAG?
Definition
Retrieval-Augmented Generation (RAG) is a method that enhances the capabilities of large language models (LLMs) by allowing them to fetch relevant information from an external knowledge base before generating a response. Instead of relying solely on their internal training data, RAG systems combine retrieval (searching for relevant documents) and generation (producing language based on those documents).
Key Points:
-
Retriever: A search component that identifies relevant content from a corpus.
-
Generator: An LLM that takes the query and retrieved documents to produce a final answer.
-
Real-time adaptability: Can respond with up-to-date knowledge without retraining.
-
Fact grounding: Answers are based on real documents, reducing hallucination.
Why RAG is Important?
Motivation: LLMs have limitations such as fixed training data, hallucinations, and difficulty in handling domain-specific queries.
Advantages of RAG:
-
Dynamic knowledge: Accesses updated data from external sources (e.g. web, private docs).
-
Lower hallucination risk: Answers are grounded in real documents.
-
Flexible and pluggable: You can attach custom knowledge bases.
-
Cost-effective updates: No need to retrain the model to integrate new knowledge.
-
Improves transparency: It’s possible to show sources of generated content.
When RAG is useful:
-
In fast-changing domains like finance or healthcare.
-
When explainability and traceability are required.
-
When serving enterprise-specific needs with private data.
RAG Foundations
Core Components
-
Retriever
-
Searches a database to find relevant documents based on the user query.
-
Uses similarity search (e.g., cosine similarity between vector embeddings).
-
Types:
-
Sparse retrievers: Traditional (e.g., BM25).
-
Dense retrievers: Modern (e.g., dual encoder models).
-
Hybrid: Combines both.
-
-
-
Generator
-
Receives the query and the retrieved content.
-
Produces a final answer using natural language.
-
Usually a pretrained model like GPT, LLaMA, or T5.
-
-
Knowledge Base (Corpus)
-
The source of truth (e.g., documents, web pages, PDFs).
-
Preprocessed into small “chunks” and embedded as vectors.
-
Stored in vector databases for efficient similarity search.
-
-
Augmentation Layer
-
Optional enhancements to improve quality:
-
Query rewriting
-
Reranking
-
Chunk compression or repacking
-
Metadata filtering
-
-
Naive RAG Pipeline
Overview
The simplest RAG pipeline involves three sequential steps:
-
Indexing
-
Documents are split into chunks.
-
Each chunk is encoded into a vector using an embedding model.
-
These vectors are stored in a vector database.
-
-
Retrieval
-
User query is also converted into a vector.
-
The top-K similar vectors (document chunks) are retrieved using similarity metrics.
-
-
Generation
-
Retrieved content is concatenated with the query.
-
The combined input is passed into an LLM for generation.
-
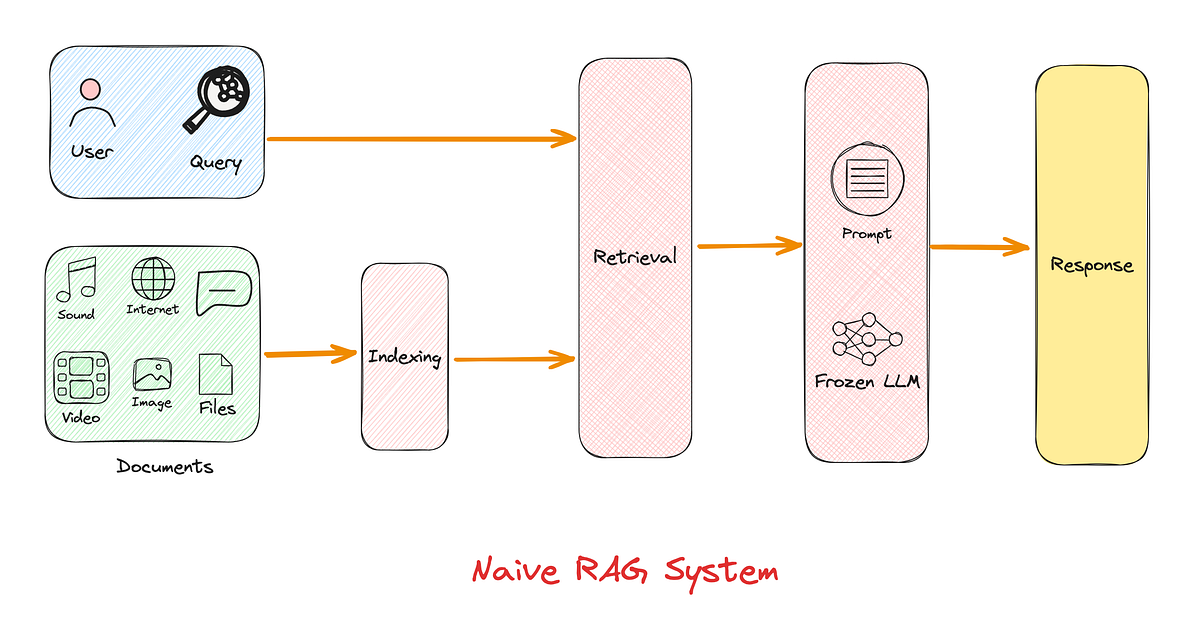
Limitations of Naive RAG:
-
May retrieve irrelevant content.
-
Doesn’t prioritize or summarize results.
-
Might cause hallucinations if bad content is retrieved.
-
Lacks control mechanisms and adaptability.
The RAG Workflow
Overview of Modules
A RAG system typically consists of several distinct processing modules. These modules represent different stages in the RAG pipeline and can be enhanced or replaced depending on the use case.
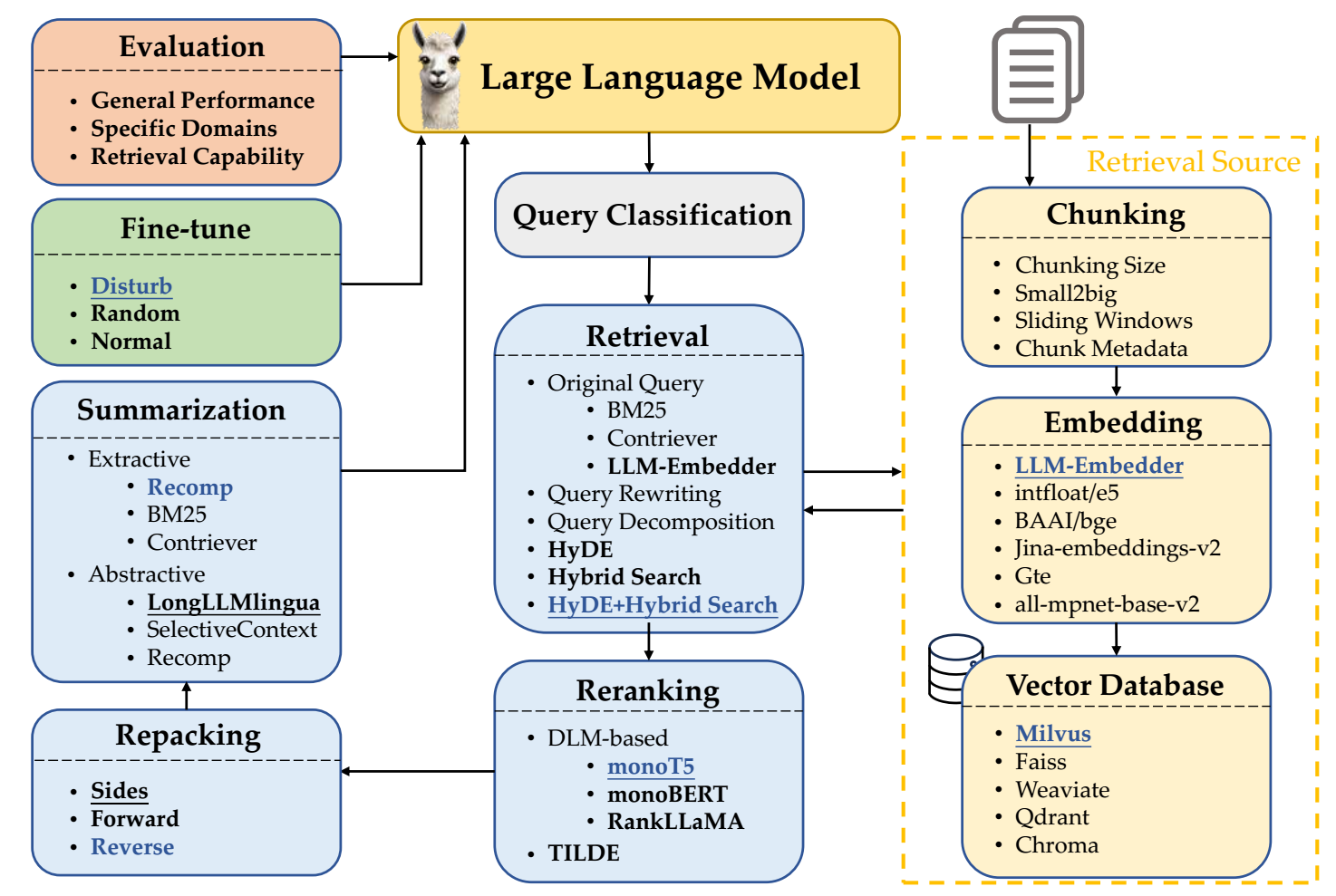
-
Query Classification
-
Purpose: To determine whether the input query needs retrieval or not.
-
Why it matters: Not all queries benefit from document retrieval. Simple factual or stylistic tasks may be better answered using the LLM alone.
-
Example: “Translate this sentence into French” doesn’t require external context.
-
Method: A classifier (like a BERT-based model) is used to predict if retrieval is needed.
-
-
Retrieval
-
Purpose: To fetch the most relevant document chunks from a corpus.
-
Steps:
-
Convert the user query to a vector.
-
Use a similarity function (dot product, cosine) to compare it with document vectors.
-
Return top-K matching chunks.
-
-
Types:
-
Original query retrieval.
-
Query rewriting to improve match quality.
-
Decomposed queries for complex inputs into series of simpler sub-questions.
-
HyDE (hypothetical document embeddings): uses an LLM to generate pseudo-docs(hypothetical answer) from the query. Then it embeds that answer and uses it to search the vector database.to enhance similarity matching.
-
-
-
Reranking
-
Purpose: To reorder the retrieved chunks based on relevance, trustworthiness, or task-specific criteria.
-
Methods:
-
Use scoring models like monoT5, RankLLaMA.
-
Score the match between each retrieved chunk and the original query.
-
Select the best-ranked documents for input to the generator.
-
-
-
Repacking
-
Purpose: To arrange retrieved content in a coherent structure before feeding it to the generator.
-
Strategies:
-
Forward: Order documents as-is (descending relevancy score).
-
Reverse: Emphasize most recent or most relevant (ascending).
-
Sides: Group documents by topic or source.
-
-
-
Summarization
-
Purpose: To reduce the size of the retrieved content so it fits within the LLM's input limit.
-
Types:
-
Extractive: segment text into sentences, then score and rank them based on importance (e.g., using BM25).
-
Abstractive: Use another LLM to rephrase and generate a summary from multiple documents (e.g., LongLLMlingua, SelectiveContext).
-
Hybrid: Combine both approaches (e.g., Recomp).
-
-
-
Generation
-
Purpose: To synthesize an answer using the query and the processed retrieved content.
-
Input: The structured, possibly summarized, repacked content + original query.
-
Output: The final user-facing response.
-
Vector Databases
Vector databases are the backbone of the retrieval process in RAG systems. They store embeddings of document chunks and enable efficient similarity-based search.
Key Features of Vector Databases:
-
Index Types: How the database organizes data for efficient lookup.
-
Scale: How much data it can handle efficiently.
-
Hybrid Search: Ability to combine vector search with keyword or metadata filtering.
-
Cloud Ready: Whether it is designed to run easily in cloud environments.
-
Notes: Special features, ecosystem, or language support.
Popular Vector Databases:
| Name | Index Types | Scale | Hybrid Search | Cloud Ready | Notes |
|---|---|---|---|---|---|
| Faiss | IVF, HNSW | Local, fast | ❌ | ❌ | High-performance C++/Python library |
| Milvus | IVF, HNSW | Billion+ | ✅ | ✅ | Scalable and enterprise-grade |
| Qdrant | HNSW | Million+ | ✅ | ✅ | Rust/Python API, cloud-native |
| Weaviate | HNSW | ~10M+ | ✅ | ✅ | Strong semantic + metadata filters |
| Chroma | HNSW (simple) | Small-medium | ✅ | ✅ (basic) | Lightweight, easy local setup |
| SurrealDB | MTREE, HNSW | Billion+ | ✅ | ✅ | Multi-model DB, integrates SQL+Vec |
Summary of the Workflow
The full RAG pipeline includes:
-
Classifying the query to see if retrieval is needed.
-
Retrieving relevant documents using similarity search.
-
Reranking results for improved precision.
-
Repacking or organizing the information.
-
Summarizing it (optional, for length or clarity).
-
Generating the final answer using an LLM.
This modular workflow allows RAG systems to be flexible, extensible, and adaptable to various real-world needs.
Key Techniques and Tools
Chunking Strategies
Chunking is the process of dividing documents into smaller, manageable pieces (called “chunks”) before storing them in the vector database. Chunking is critical because LLMs and retrievers work better when each unit of content is coherent, compact, and semantically meaningful.
Types of Chunking:
-
Token-Level Chunking
-
Splits documents based on token count.
-
Simple but may cut through sentences or break context.
-
Often used in systems with strict token budgets.
-
⚠️ Risk: May reduce semantic relevance.
-
-
Sentence-Level Chunking
-
Breaks text at sentence boundaries.
-
Balances semantic coherence with manageable length.
-
Most commonly used in production systems.
-
✅ Recommended for general-purpose RAG systems.
-
-
Semantic-Level Chunking
-
Uses LLMs to determine natural breakpoints based on meaning.
-
Most context-preserving but also the most expensive.
-
Great for long-form content like books, reports, or research.
-
Advanced Chunking Techniques:
-
Sliding Window
-
Creates overlapping chunks to preserve context across splits.
-
Example: 512-token chunks with 20-token overlap.
-
Reduces risk of splitting crucial information across chunks.
-
-
Small-to-Big (S2B)
-
Retrieves small precise chunks.
-
Then expands to include their parent (larger) chunks for full context.
-
Improves both precision and recall in retrieval.
-
Embedding Models
Embedding models transform text into high-dimensional vectors that represent semantic meaning. The quality of these embeddings is crucial for effective retrieval.
Key Considerations:
-
Must support both the query and the document chunks.
-
Should be trained or fine-tuned on similar types of text.
-
Trade-off: Smaller models are faster; larger models are more accurate.
Common Embedding Models:
| Model Name | Type | Notes |
|---|---|---|
| intfloat/e5-small-v2 | Dense | Lightweight and fast; good baseline |
| intfloat/e5-large-v2 | Dense | More accurate; used for robust retrieval |
| BAAI/bge-small-en | Dense | High-quality general-purpose model |
| BAAI/bge-large-en-v1.5 | Dense | One of the most accurate public models |
| GTE-base / GTE-small | Dense | Lightweight alternatives by Alibaba |
| all-mpnet-base-v2 | Dense | From SentenceTransformers; widely used baseline |
| Jina Embeddings v2 | Dense | Optimized for semantic search |
Choosing a Model:
- for production use we went with
nomic-embed-text.
Metadata Usage
Metadata is structured information attached to each chunk, such as:
-
Title: The section or page title.
-
Document name: Source identifier.
-
Timestamp: When the content was written.
-
Tags: Category, topic, or relevance labels.
-
Chunk index: Position of the chunk in the document.
Why Metadata Matters:
-
Improved filtering
Enables scoped searches (e.g., “search only in policy documents”).
-
Better reranking
Use metadata features to boost certain types of results.
-
Transparency
Makes it easier to display source context in the output (e.g., citations).
-
Routing
Can help guide queries to specialized retrievers (e.g., legal vs. medical corpora).
Summary
This chapter covered foundational techniques to optimize retrieval in RAG systems:
-
Chunking: How you split your data matters. Sliding windows and semantic chunking improve quality.
-
Embedding: Choose the right model for your use case; accuracy vs. speed trade-off.
-
Metadata: Use it for better control, filtering, and relevance.
Advanced and Modular RAG
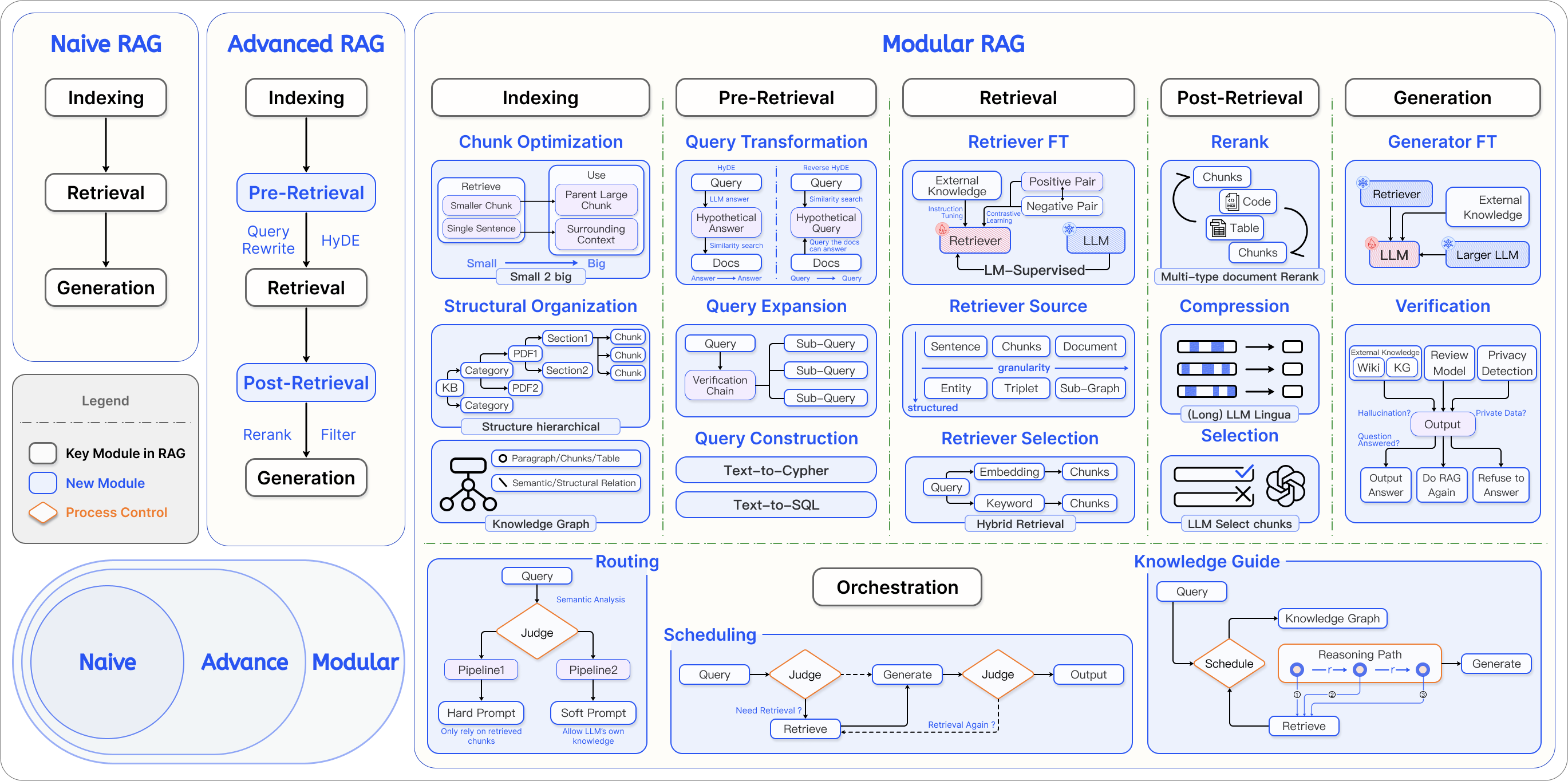
Advanced RAG Improvements
Advanced RAG refers to systems that build upon the limitations of Naive RAG by optimizing both retrieval and generation using additional strategies.
Pre-Retrieval Enhancements
These are techniques applied before fetching documents:
-
Query Rewriting
-
Rephrases or expands the user query to better match stored documents.
-
Example: Rewriting “LLM” → “large language model”.
-
-
Query Expansion
-
Adds additional terms or synonyms to improve recall.
-
Useful in domain-specific vocabularies or ambiguous queries.
-
-
Multi-query Retrieval
-
Splits the user query into several sub-queries, retrieves separately, and merges results.
-
Helps cover more ground and improve completeness.
-
-
Use of Metadata Filters
-
Filters retrieval using metadata (e.g., document_type = "FAQ").
-
Increases precision by eliminating irrelevant sections.
-
Post-Retrieval Enhancements
These are applied after initial document retrieval, before feeding them to the generator:
-
Reranking
-
Uses a secondary model to reorder retrieved documents by semantic relevance.
-
Can be done using cross-encoders or reranking LLMs.
-
-
Context Compression
-
Reduces retrieved content using summarization or token pruning.
-
Helps fit more content within LLM token limits.
-
-
Repacking and Ordering
-
Rearranges documents to improve logical flow.
-
Example: Grouping by source or time, sorting by importance.
-
Modular RAG
Modular RAG systems evolve from rigid pipelines into reconfigurable architectures, where each stage is represented as a module. These systems are flexible, scalable, and easier to debug or extend.
Core Concepts of Modular RAG:
-
Modules
-
Represent high-level stages like retrieval, summarization, generation, orchestration.
-
Can be replaced or extended independently.
-
-
Sub-Modules
- Functional units inside modules (e.g., reranking inside the retrieval module).
-
Operators
- Lowest-level functional units (e.g., cosine similarity, token eliminator, prompt formatter).
-
Orchestration
- A control unit that dynamically routes queries through different modules depending on context or task.
Common Flow Patterns
Modular RAG systems are flexible enough to support multiple interaction patterns between modules. These allow more powerful and intelligent workflows.
✅ Common Flow Patterns:
| Flow | Pattern | Description |
|---|---|---|
| Linear | Classic RAG: query → retrieve → generate | |
| Rewrite-Retrieve-Read | Query is rewritten before retrieval | retrieval is optimized for better inputs |
| Demonstrate-Search-Predict (DSP) | Uses few-shot examples and routing | logic for tailored retrieval |
| Iterative Retrieve-Read | The model retrieves multiple rounds before | generation |
| Self-RAG | The model decides whether to retrieve or not at all | |
| Generate-Read | The LLM generates hypothetical answers, then retrieves | documents to support them |
Advantages of Modular RAG
-
Flexibility: Modules can be customized for different use cases.
-
Adaptability: System can decide its own execution flow.
-
Maintainability: Easier to debug or improve specific modules.
-
Scalability: Handles more data sources, tasks, and formats.
RAG vs. Other LLM Enhancement Techniques
As LLMs evolve, three common methods have emerged to enhance their knowledge capabilities and task performance:
-
Prompt Engineering
-
Fine-Tuning
-
Retrieval-Augmented Generation (RAG)
Each of these methods has different strengths, trade-offs, and ideal use cases.
Fine-tuning vs. RAG
Fine-tuning involves modifying the internal weights of an LLM by training it on new data. This process is computationally expensive but results in a more deeply adapted model.
🔍 Fine-tuning
-
Definition: Training the model on a new dataset to adjust its behavior permanently.
-
Types:
-
Supervised fine-tuning (SFT): Learn from labeled examples.
-
Instruction-tuning: Learn from instructions and demonstrations.
-
Reinforcement learning: Optimize output quality through feedback loops.
-
✅ Advantages:
-
Produces highly tailored behavior and tone.
-
No external retrieval needed.
-
Lower latency at inference time.
⚠️ Disadvantages:
-
Costly (compute + time).
-
Static: doesn't adapt to real-time data.
-
Hard to audit or update knowledge.
🔁 RAG
-
Definition: Uses an external retriever to supply relevant context before generation.
-
Behavior: Instead of “teaching” the model, RAG lets it “read” external documents live.
✅ Advantages:
-
Real-time adaptability.
-
Transparent (can show sources).
-
Cheaper and faster to update (no retraining).
⚠️ Disadvantages:
-
Slightly slower due to retrieval step.
-
Needs well-maintained document storage (corpus + vector DB).
-
More moving parts (retrievers, rerankers, etc.).
Prompt Engineering vs. RAG
Prompt Engineering is the practice of designing better prompts to steer the behavior of LLMs, without modifying the model or using external data.
🔧 Prompt Engineering
-
Examples:
-
Few-shot prompting: Provide examples in the prompt.
-
Zero-shot reasoning: Use specific instructions like “Let's think step by step.”
-
✅ Advantages:
-
Fast and easy to implement.
-
No additional infrastructure required.
-
Useful for creative or format-based tasks.
⚠️ Disadvantages:
-
Limited by what the model already knows.
-
Cannot add new factual knowledge.
-
Less reliable for complex or high-risk domains.
📊 Comparison Table
| Method | External Knowledge | Model Update Required | Cost to Update | Transparency | Use Case Examples |
|---|---|---|---|---|---|
| Prompt Engineering | ❌ No | ❌ No | 💰 Very Low | ❌ Low | Style guides, code formatting, logic tasks |
| Fine-Tuning | ❌ No (internalized) | ✅ Yes (retrain) | 💰💰 Very High | ❌ Low | Chatbots, brand tone, domain adaptation |
| RAG | ✅ Yes | ❌ No | 💰 Medium | ✅ High | QA systems, real-time tools, data assistants |
Summary
-
Fine-tuning is ideal for permanent, deeply integrated behaviors — but it's costly and static.
-
Prompt engineering is quick and useful, but can't overcome knowledge limits.
-
RAG provides the best balance for dynamic, reliable, and explainable AI in knowledge-intensive environments.
Evaluation of RAG Systems
Evaluating RAG systems is more complex than evaluating traditional LLMs, because RAG involves two distinct processes:
-
Retrieval quality
-
Generation quality (based on retrieved documents)
A good RAG system must fetch relevant documents and generate coherent, factually correct, and context-aware responses.
Metrics
Evaluation can be split into three levels:
- Retrieval-Level Metrics
These measure how relevant the retrieved documents are to the query.
-
Recall@k: Measures if the correct document appears in the top-k results.
-
Precision@k: Measures the proportion of top-k results that are relevant.
-
Mean Reciprocal Rank (MRR): Focuses on the rank of the first relevant document.
-
Normalized Discounted Cumulative Gain (NDCG): Gives more credit for relevant documents appearing higher in the list.
- Generation-Level Metrics
These assess the quality of the final output from the LLM, given the retrieved context.
-
BLEU / ROUGE / METEOR: Compare generated output with reference texts using n-gram overlap.
-
BERTScore: Uses embeddings instead of raw tokens to compare semantic similarity.
-
GPTScore / LLM-as-a-Judge: Use another LLM to assess answer quality (faithfulness, helpfulness, etc.).
- End-to-End Metrics (Human-Centric)
Used to assess the system as a whole from the user’s perspective.
-
Faithfulness: Is the generated answer actually grounded in the retrieved docs?
-
Helpfulness: Does the response actually address the user's need?
-
Toxicity / Bias: Are responses free of harmful or offensive content?
-
Latency: Total time taken from query to response.
Datasets and Benchmarks
Evaluation requires standardized datasets with known answers. Here are commonly used ones for RAG:
| Dataset / Benchmark | Task Type | Domain | Description |
|---|---|---|---|
| Natural Questions (NQ) | Open-domain QA | General | Questions with long + short answers |
| TriviaQA | Open-domain QA | Trivia | Multi-sentence answers with evidence |
| HotpotQA | Multihop QA | Wikipedia | Requires combining facts from multiple docs |
| FEVER | Fact verification | Wikipedia | Verify claims with evidence |
| ELI5 | Long-form QA | Requires lengthy, detailed answers | |
| MS MARCO | Passage retrieval | Web | Large-scale IR task; used to test retrievers |
| BEIR Benchmark | Retrieval (multi) | Mixed | Massive suite of 18+ retrieval datasets |
Notable Tools:
-
BEIR Benchmark: Covers multiple retrieval tasks in diverse domains.
-
OpenAI Eval / LLM-as-a-Judge: Uses LLMs like GPT-4 to grade model responses.
-
LangChain + LlamaIndex: Useful for custom eval pipelines using RAG.
Summary
-
Evaluating RAG = evaluating both retrieval and generation quality.
-
Use retrieval metrics (Recall@k, MRR) and generation metrics (ROUGE, BERTScore).
-
Use benchmarks like NQ, HotpotQA, and BEIR for testing.
-
For nuanced tasks, consider LLM-based evaluation as a modern alternative.
Real-World Applications
Retrieval-Augmented Generation (RAG) systems have found widespread application across industries. Their ability to deliver accurate, up-to-date, and traceable outputs makes them especially valuable in domains that demand precision, adaptability, and transparency.
| Domain | Use Case | Benefit of RAG |
|---|---|---|
| Healthcare | Medical Q&A Assistant | Up-to-date answers, evidence-backed explanations |
| Legal | Legal Research & Summaries | Cited rulings, reduced risk of hallucination |
| Education | Personalized Tutor Chatbots | Textbook-grounded answers, interactive learning |
| Customer Support | AI FAQ / Helpdesk Bots | Company docs as ground truth, auto-updating |
| E-Commerce | Shopping Assistants, Product Chatbots | Catalog-aware, review-based explanations |
| Journalism | Fact-checking, News Summaries | Cross-source synthesis, cited claims |
| Developer Tools | Code Q&A, API Docs Assistants | Context-aware, version-specific documentation |
Challenges and Future Directions
As powerful as RAG systems are, they still face a range of challenges, especially in real-world deployment. Understanding these limitations is crucial for building reliable, scalable, and efficient applications.
Common Challenges
-
Retrieval Noise and Irrelevance
-
Retrieved chunks may contain:
-
Repeated information
-
Marginally relevant content
-
Contradictory or misleading data
-
-
Impact: Can confuse the generator or lead to hallucinated answers.
-
Solution: Reranking, metadata filters, and query rewriting.
-
-
Query Ambiguity and Under-Specification
-
User queries may be:
-
Too vague (“Tell me about the law”)
-
Using overloaded terms (e.g., “LLM” = Large Language Model or Master of Laws)
-
-
Impact: Poor retrieval due to mismatches.
-
Solution: Query rewriting, sub-query decomposition, classification modules.
-
-
Token and Context Limits
-
LLMs have a strict input token limit (e.g., 8k–100k tokens).
-
Long retrieved content must be:
-
Compressed
-
Summarized
-
Selected selectively
-
-
Impact: Truncated or low-quality input reduces answer quality.
-
-
Latency and Cost
-
RAG systems involve:
-
Document retrieval
-
Vector encoding
-
LLM inference
-
-
Impact: Increased response time and operational costs.
-
Solution: Caching, query classification (skip retrieval when not needed), smaller models.
-
-
Evaluation Complexity
-
Hard to measure performance consistently because:
-
Retrieval and generation quality are interdependent.
-
No universal benchmarks for all domains.
-
-
Solution: Combine automated and human-based evaluation (LLM-as-a-judge + manual review).
-
-
Domain-Specific Knowledge Integration
-
RAG struggles with:
-
Highly specialized vocabularies (e.g., legal citations, scientific formulas).
-
Tables, charts, and non-textual data.
-
-
Impact: Loss of critical context.
-
Solution: Use structured data (e.g., SQL + RAG), convert tables to text, or train with examples.
-
-
Security, Bias, and Misinformation
-
If the knowledge base is not curated:
- RAG may surface outdated, biased, or even harmful content.
-
Impact: Erosion of user trust or factual correctness.
-
Solution: Source filtering, content audits, feedback loops.
-
Future Research
-
Adaptive Retrieval and Dynamic Routing
-
Systems like Self-RAG and DSP explore:
-
Skipping retrieval for simple queries.
-
Using learned decision-making to route queries differently.
-
-
Goal: More intelligent, efficient, and personalized pipelines.
-
-
Multimodal RAG (Text + Image + Audio)
-
Future RAG systems will support:
-
Image-grounded retrieval (e.g., PDF diagrams)
-
Video summarization
-
Spoken input and output
-
-
Impact: Makes RAG usable across education, media, and accessibility.
-
-
Structured + Unstructured Hybrid Retrieval
-
Combine:
-
Text documents
-
Tables, databases (SQL, NoSQL)
-
Graph data (Knowledge Graphs)
-
-
Example: A finance chatbot pulls both annual report paragraphs and stock prices from a SQL database.
-
-
Feedback Loops and Learning from User Interactions
-
Future RAG systems will:
-
Log user corrections or upvotes
-
Re-rank or adapt based on usage
-
Learn from mistakes like hallucination
-
-
-
Model-Retriever Co-Training
-
Train the retriever and generator together end-to-end.
-
Improves alignment between what’s retrieved and what’s generated.
-
Still a cutting-edge research area.
-
-
Cross-Lingual and Multilingual RAG
-
Allow queries and documents to be in different languages.
-
Expands RAG use cases globally.
-
Requires multilingual embeddings and language-aware retrievers.
-
Summary
RAG is still evolving rapidly. While it already powers many practical AI applications, its future lies in:
-
More flexible and modular systems.
-
Better context awareness and content understanding.
-
Integration with structured knowledge.
-
Feedback-aware and adaptive pipelines.
RAG is not just a workaround for hallucinations — it’s a next-generation paradigm for building truthful, grounded, and intelligent AI systems.
📚 References & Inspiration
The book is inspired by cutting-edge research:
- 📖 RAG Survey (2023) – Overview of RAG methods and design choices.
- 🧱 Modular RAG (2024) – Best practices for building modular RAG systems.
- 🧠 RAG Best Practices (2024) – Techniques for scalable and robust RAG architectures.